
Direct S3 Access GEDI L4A from the NASA Earthdata Cloud#
GEDI L4A Datasets are available through NASA’s Earthdata Cloud. In this tutorial, we will retrieve Global Ecosystem Dynamics Investigation (GEDI) L4A Footprint Level Aboveground Biomass Density (AGBD)[Dubayah et al., 2022] dataset from the Earthdata Cloud using direct S3 access.
NASA Earthdata on Cloud is always free and accessible via either HTTPS or direct S3 bucket access. With direct S3 access, you can bring your “code to the data”, making your processing faster and scalable. Direct S3 access to NASA Earthdata on Cloud is only available if your Amazon Web Services (AWS) instance is set up in the us-west-2 region. If you are new to the Earthdata Cloud, these NASA Earthdata primers and tutorials are good resources to get you started.
You can access jupyter notebook within your own AWS EC2 instance. Alternatively, you can use Amazon SageMaker Studio Lab to run this jupyter notebook. SageMaker Studio Lab is a free service that gives access to AWS compute resources and direct S3 access to datasets in the NASA Earthdata Cloud through a JupyterLab environment.
Learning Objectives
Download and subset GEDI L4A datasets using direct S3 access
Requirements#
This tutorial should be run on the Cloud, such as a Jupyter Lab instance running in AWS us-west 2 region. Additional prerequisites for running this Jupyter notebook are provided here.
# import python modules
import h5py
import earthaccess
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
from shapely.ops import orient
from pqdm.processes import pqdm
1. Polygonal Area of Interest#
We will read an area within the Harvard Forests as a GeoJSON file. The Harvard Forests is one of the most extensively studied ecological sites in the United States.
If an area of interest is already defined as a polygon, the polygon file (geojson, shapefile, or kml) can be used to find overlapping GEDI L4A files. More details about this capability are described on this page.
# read geojson
poly = gpd.read_file("polygons/harvard.json")
poly.explore(color='red', fill=False)
2. Searching GEDI L4A Files#
We will use the earthaccess module to query spatially overlapping GEDI L4A granules.
# bounding lon, lat as a list of tuples
bounds = poly.geometry.apply(orient, args=(1,))
# simplifying the polygon to bypass the coordinates
# limit of the CMR with a tolerance of .01 degrees
xy = bounds.simplify(0.01).get_coordinates()
granules = earthaccess.search_data(
doi="10.3334/ORNLDAAC/2056", # GEDI L4A DOI
polygon=list(zip(xy.x, xy.y))
)
print(f"Total granules found: {len(granules)}")
Total granules found: 37
Let’s retrieve direct s3 links from the above earthaccess search_data results.
granule_arr=[]
for g in granules:
granule_arr.append(g.data_links(access="direct")[0])
Now, the granule_arr contains a list of s3 granule links, starting with s3://. We can print the first two items of the granule_arr.
granule_arr = sorted(granule_arr)
granule_arr[:2]
['s3://ornl-cumulus-prod-protected/gedi/GEDI_L4A_AGB_Density_V2_1/data/GEDI04_A_2019229131935_O03846_02_T03642_02_002_02_V002.h5',
's3://ornl-cumulus-prod-protected/gedi/GEDI_L4A_AGB_Density_V2_1/data/GEDI04_A_2019246121050_O04109_03_T04380_02_002_02_V002.h5']
Let’s plot the monthly number of granules overlapping the above area within the Harvard Forest.
fmt = '%Y%j%H%M%S' # GEDI granule name has date time as YYYYDDDHHMMSS
granule_dt = [g.split('/')[-1].split('_')[2] for g in granule_arr]
df = pd.DataFrame(list(zip(granule_dt, granule_arr)), columns =['datetime', 'Granules #'])
df['datetime'] = pd.to_datetime(df['datetime'], format=fmt)
df.set_index('datetime', inplace=True)
# plotting a monthly granule count plot
title = f'''Number of GEDI L4A granules (n = {len(granule_arr)}) over Harvard Forests by month
over period {df.index.min()} to {df.index.max()} '''
ax = df.groupby(df.index.to_period('M')).agg('count').plot(style='o--', markersize=7, title=title)
ax.set_ylabel("# of granules")
plt.show()
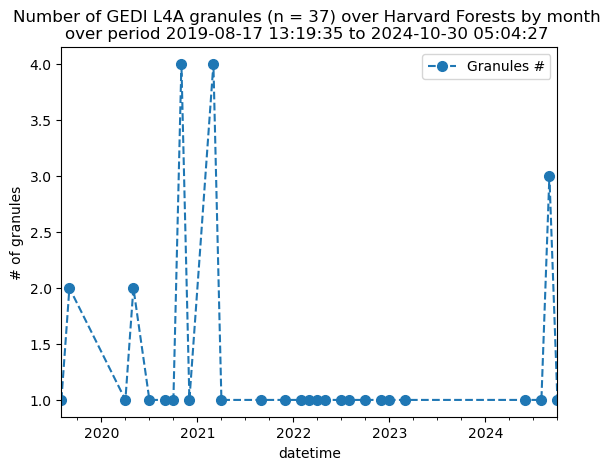
As we see in the figure above, over the Harvard Forest area, some months do not have overlapping GEDI granules while some months have up to four granules.
3. Direct S3 access#
We recommend using earthaccess to download GEDI data granules from the NASA Earthdata. You will first need to authenticate your Earthdata Login (EDL) information using the earthaccess python library as follows:
# works if the EDL login already been persisted to a netrc
try:
auth = earthaccess.login(strategy="netrc")
except FileNotFoundError:
# ask for EDL credentials and persist them in a .netrc file
auth = earthaccess.login(strategy="interactive", persist=True)
For this tutorial, we will be retrieving the AGBD variables agbd and l4_quality_flag, in addition to the variables that provide geolocation (lat_lowestmode, lon_lowestmode, elev_lowestmode) and shot identifier (shot_number).
def gedi_l4a_subset(gr):
headers = ['lat_lowestmode', 'lon_lowestmode', 'elev_lowestmode', 'shot_number']
variables = ['agbd', 'l4_quality_flag']
headers.extend(variables)
polygon = gpd.read_file("polygons/harvard.json")
dfs = []
with h5py.File(gr) as hf:
beam_names = filter(lambda x: x.startswith('BEAM'), list(hf.keys()))
for var in beam_names:
# create pandas dataframe
df = pd.DataFrame({'lat_lowestmode': hf[var]['lat_lowestmode'],
'lon_lowestmode': hf[var]['lon_lowestmode']})
# create geopandas dataframe
gdf = gpd.GeoDataFrame(df, crs="EPSG:4326",
geometry=gpd.points_from_xy(df.lon_lowestmode,
df.lat_lowestmode))
# subset within the polygon
poly_gdf = gpd.sjoin(gdf, polygon, predicate='within')
if not poly_gdf.empty:
for v in headers[2:]:
poly_gdf[v] = None
# retrieving variables of interest, agbd, l4_quality_flag in this case.
# We are only retreiving the shots within subset area.
for _, df_gr in poly_gdf.groupby((poly_gdf.index.to_series().diff() > 1).cumsum()):
i = df_gr.index.min()
j = df_gr.index.max()
for v in variables:
poly_gdf.loc[i:j, (v)] = hf[var][v][i:j+1]
# appending to the output file if valid agbd
poly_gdf = poly_gdf[poly_gdf['agbd'] != -9999]
if not poly_gdf.empty:
dfs.append(poly_gdf)
if dfs:
return pd.concat(dfs)
# parallelize tqdm runs using processes
result = pqdm(earthaccess.open(granules), gedi_l4a_subset, n_jobs=8)
# concatenate pandas dataframe
l4a_gdf = pd.concat([x for x in result if x is not None])
We will now plot the AGBD (mg/ha-1) values of the footprints on a map.
xyz = "https://server.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer/tile/{z}/{y}/{x}"
attr = "ESRI"
l4a_gdf['agbd'] = l4a_gdf['agbd'].astype(float)
l4a_gdf[['agbd', 'l4_quality_flag', 'geometry']].explore("agbd", cmap = "YlGn",
tiles=xyz, attr=attr, legend=True)
# (optional) export to csv
l4a_gdf.to_csv('poly_subset.csv', index=False)
References#
R.O. Dubayah, J. Armston, J.R. Kellner, L. Duncanson, S.P. Healey, P.L. Patterson, S. Hancock, H. Tang, J. Bruening, M.A. Hofton, J.B. Blair, and S.B. Luthcke. GEDI L4A Footprint Level Aboveground Biomass Density, Version 2.1. 2022. doi:10.3334/ORNLDAAC/2056.