GEDI Aboveground Biomass#
Overview#
This tutorial will demonstrate how to directly access and subset the GEDI L2A canopy height metrics and L4A aboveground biomass dataset using NASA’s Harmony Services and compute a summary of aboveground biomass density for a forest reserve. The Harmony API allows seamless access and production of analysis-ready Earth observation data across different DAACs by enabling cloud-based spatial, temporal, and variable subsetting and data conversions. The GEDI datasets are available from the Harmony API.
Learning Objectives
Use NASA’s Harmony Services to retrieve the GEDI L2A and L4A datasets. The Harmony API allows access to selected variables for the dataset within the spatial-temporal bounds without having to download the whole data file.
Compute summaries of AGBD across various plant functional types (PFTs) and canopy heights (RH100) in the study area.
Dataset#
The Global Ecosystem Dynamics Investigation (GEDI) L4A Footprint Level Aboveground Biomass Density (AGBD) dataset [Dubayah et al., 2022] provides predictions of the aboveground biomass density (AGBD; in Mg/ha) and estimates of the prediction standard error within each sampled geolocated GEDI footprint. The GEDI Level 2A Geolocated Elevation and Height Metrics product (GEDI02_A) [Dubayah et al., 2021] provides waveform interpretation and extracted products from eachreceived waveform, including ground elevation, canopy top height, and relative height (RH) metrics. GEDI datasets are available for the period starting 2019-04-17 and covers 52 N to 52 S latitudes. GEDI L2A and L4A data files are natively in HDF5 format.
R. Dubayah, M. Hofton, J. Blair, J. Armston, H. Tang, and S. Luthcke. GEDI L2A Elevation and Height Metrics Data Global Footprint Level V002. 2021. doi:10.5067/GEDI/GEDI02_A.002.
R.O. Dubayah, J. Armston, J.R. Kellner, L. Duncanson, S.P. Healey, P.L. Patterson, S. Hancock, H. Tang, J. Bruening, M.A. Hofton, J.B. Blair, and S.B. Luthcke. GEDI L4A Footprint Level Aboveground Biomass Density, Version 2.1. 2022. doi:10.3334/ORNLDAAC/2056.
import h5py
import requests as re
import pandas as pd
import geopandas as gpd
import contextily as ctx
import matplotlib.pyplot as plt
from datetime import datetime
from glob import glob
from harmony import Client, Collection, Environment, Request
import seaborn as sns
from os import path
sns.set(style='whitegrid')
Authentication#
NASA Harmony API requires NASA Earthdata Login (EDL). You can use the earthaccess Python library to set up authentication. Alternatively, you can also login to harmony_client directly by passing EDL authentication as the following in the Jupyter Notebook itself:
harmony_client = Client(auth=("your EDL username", "your EDL password"))
Create Harmony Client Object#
First, we create a Harmony Client object. If you are passing the EDL authentication, please do as shown above with the auth parameter.
harmony_client = Client()
Retrieve Concept ID#
Now, let’s retrieve the Concept ID of the GEDI L4A dataset. The Concept ID is NASA Earthdata’s unique ID for its dataset.
def get_concept_id(doi):
"""get concept id from DOI using CMR API"""
doisearch = f'https://cmr.earthdata.nasa.gov/search/collections.json?doi={doi}'
return re.get(doisearch).json()['feed']['entry'][0]['id']
concept_l4a = get_concept_id('10.3334/ORNLDAAC/2056') # GEDI L4A DOI
concept_l2a = get_concept_id( '10.5067/GEDI/GEDI02_A.002') # GEDI L2A DOI
# printing concept_ids
print(f"{concept_l4a}, {concept_l2a}")
C2237824918-ORNL_CLOUD, C2142771958-LPCLOUD
Define Request Parameters#
Let’s create a Harmony Collection object with the concept_id retrieved above. We will also define the GEDI L4A variables of interest and temporal range.
# harmony collection
collection_l4a = Collection(id=concept_l4a)
collection_l2a = Collection(id=concept_l2a)
def create_var_names(variables):
# gedi beams
beams = ['BEAM0000', 'BEAM0001', 'BEAM0010', 'BEAM0011', 'BEAM0101', 'BEAM0110', 'BEAM1000', 'BEAM1011']
# combine variables and beam names
return [f'/{b}/{v}' for b in beams for v in variables]
# gedi variables
variables_l4a = create_var_names(['agbd', 'l4_quality_flag', 'land_cover_data/pft_class'])
variables_l2a = create_var_names(['rh'])
# time range
temporal_range = {'start': datetime(2019, 4, 17),
'stop': datetime(2023, 3, 31)}
We will use the spatial extent of the Reserva Florestal Adolpho Ducke, a forest reserve near Manaus, Brazil, provided as a GeoJSON file at assets/reserva_ducke.json. Let’s open and plot this file.
poly_json = 'assets/reserva_ducke.json'
poly = gpd.read_file(poly_json)
poly.explore(color='red', fill=False)
Create and Submit Harmony Request#
Now, we can create a Harmony request with variables, temporal range, and bounding box and submit the request using the Harmony client object. We will use the download_all method, which uses a multithreaded downloader and returns a concurrent future. Futures are asynchronous and let us use the downloaded file as soon as the download is complete while other files are still being downloaded.
def submit_harmony(collection, variables):
"""submit harmony request"""
request = Request(collection=collection,
variables=variables,
temporal=temporal_range,
shape=poly_json,
ignore_errors=True)
# submit harmony request, will return job id
subset_job_id = harmony_client.submit(request)
print(f'Processing job: {subset_job_id}')
print(f'Waiting for the job to finish')
results = harmony_client.result_json(subset_job_id, show_progress=True)
print(f'Downloading subset files...')
futures = harmony_client.download_all(subset_job_id, directory="downloads", overwrite=True)
for f in futures:
# all subsetted files have this suffix
if f.result().endswith('subsetted.h5'):
print(f'Downloaded: {f.result()}')
print(f'Done downloading files.')
submit_harmony(collection_l4a, variables_l4a)
submit_harmony(collection_l2a, variables_l2a)
Processing job: ad23d3e3-59dc-4657-935f-3936643f202f
Waiting for the job to finish
[ Processing: 61% ] |############################### | [/]
Job is running with errors.
[ Processing: 100% ] |###################################################| [|]
Downloading subset files...
downloads/75813910_GEDI04_A_2019193112046_O03286_04_T04871_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813910_GEDI04_A_2019193112046_O03286_04_T04871_02_002_02_V002_subsetted.h5
downloads/75813909_GEDI04_A_2019167212927_O02889_04_T02025_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813909_GEDI04_A_2019167212927_O02889_04_T02025_02_002_02_V002_subsetted.h5
downloads/75813911_GEDI04_A_2019223115656_O03752_01_T00916_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813911_GEDI04_A_2019223115656_O03752_01_T00916_02_002_02_V002_subsetted.h5
downloads/75813912_GEDI04_A_2019242043202_O04042_01_T02492_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813912_GEDI04_A_2019242043202_O04042_01_T02492_02_002_02_V002_subsetted.h5
downloads/75813913_GEDI04_A_2019287103704_O04744_01_T03762_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813913_GEDI04_A_2019287103704_O04744_01_T03762_02_002_02_V002_subsetted.h5
downloads/75813914_GEDI04_A_2020193231025_O08954_01_T00916_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813914_GEDI04_A_2020193231025_O08954_01_T00916_02_002_02_V002_subsetted.h5
downloads/75813915_GEDI04_A_2021123022615_O13529_01_T08031_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813915_GEDI04_A_2021123022615_O13529_01_T08031_02_002_02_V002_subsetted.h5
downloads/75813916_GEDI04_A_2021158000720_O14070_04_T07717_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813916_GEDI04_A_2021158000720_O14070_04_T07717_02_002_02_V002_subsetted.h5
downloads/75813917_GEDI04_A_2021161223427_O14131_04_T08987_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813917_GEDI04_A_2021161223427_O14131_04_T08987_02_002_02_V002_subsetted.h5
downloads/75813919_GEDI04_A_2022011094600_O17455_04_T10563_02_002_02_V002_subsetted.h5
Downloaded: downloads/75813919_GEDI04_A_2022011094600_O17455_04_T10563_02_002_02_V002_subsetted.h5
downloads/75813922_GEDI04_A_2022260193142_O21323_01_T02492_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813922_GEDI04_A_2022260193142_O21323_01_T02492_02_003_01_V002_subsetted.h5
downloads/75813923_GEDI04_A_2022287090113_O21735_01_T08031_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813923_GEDI04_A_2022287090113_O21735_01_T08031_02_003_01_V002_subsetted.h5
downloads/75813924_GEDI04_A_2022325174926_O22330_01_T03762_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813924_GEDI04_A_2022325174926_O22330_01_T03762_02_003_01_V002_subsetted.h5
Done downloading files.
Processing job: 0697d20d-cfab-4748-9e4c-c3a39e7d01cf
Waiting for the job to finish
[ Processing: 78% ] |####################################### | [|]
Job is running with errors.
[ Processing: 100% ] |###################################################| [|]
Downloading subset files...
downloads/75813935_GEDI02_A_2021161223427_O14131_04_T08987_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813935_GEDI02_A_2021161223427_O14131_04_T08987_02_003_02_V002_subsetted.h5
downloads/75813933_GEDI02_A_2021123022615_O13529_01_T08031_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813933_GEDI02_A_2021123022615_O13529_01_T08031_02_003_02_V002_subsetted.h5
downloads/75813934_GEDI02_A_2021158000720_O14070_04_T07717_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813934_GEDI02_A_2021158000720_O14070_04_T07717_02_003_02_V002_subsetted.h5
downloads/75813928_GEDI02_A_2019193112046_O03286_04_T04871_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813928_GEDI02_A_2019193112046_O03286_04_T04871_02_003_01_V002_subsetted.h5
downloads/75813927_GEDI02_A_2019167212927_O02889_04_T02025_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813927_GEDI02_A_2019167212927_O02889_04_T02025_02_003_01_V002_subsetted.h5
downloads/75813930_GEDI02_A_2019242043202_O04042_01_T02492_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813930_GEDI02_A_2019242043202_O04042_01_T02492_02_003_02_V002_subsetted.h5
downloads/75813932_GEDI02_A_2020193231025_O08954_01_T00916_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813932_GEDI02_A_2020193231025_O08954_01_T00916_02_003_01_V002_subsetted.h5
downloads/75813940_GEDI02_A_2022260193142_O21323_01_T02492_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813940_GEDI02_A_2022260193142_O21323_01_T02492_02_003_02_V002_subsetted.h5
downloads/75813931_GEDI02_A_2019287103704_O04744_01_T03762_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813931_GEDI02_A_2019287103704_O04744_01_T03762_02_003_01_V002_subsetted.h5
downloads/75813942_GEDI02_A_2022325174926_O22330_01_T03762_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813942_GEDI02_A_2022325174926_O22330_01_T03762_02_003_02_V002_subsetted.h5
downloads/75813937_GEDI02_A_2022011094600_O17455_04_T10563_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813937_GEDI02_A_2022011094600_O17455_04_T10563_02_003_02_V002_subsetted.h5
downloads/75813929_GEDI02_A_2019223115656_O03752_01_T00916_02_003_01_V002_subsetted.h5
Downloaded: downloads/75813929_GEDI02_A_2019223115656_O03752_01_T00916_02_003_01_V002_subsetted.h5
downloads/75813941_GEDI02_A_2022287090113_O21735_01_T08031_02_003_02_V002_subsetted.h5
Downloaded: downloads/75813941_GEDI02_A_2022287090113_O21735_01_T08031_02_003_02_V002_subsetted.h5
Done downloading files.
Read Subset files#
All the subsetted files are saved as _subsetted.h5. Let’s read these h5 files into the pandas dataframe.
def read_gedi_vars(beam):
"""reads through gedi variable hierarchy"""
col_names = []
col_val = []
# read all variables
for key, value in beam.items():
# check if the item is a group
if isinstance(value, h5py.Group):
# looping through subgroups
for key2, value2 in value.items():
col_names.append(key2)
col_val.append(value2[:].tolist())
else:
col_names.append(key)
col_val.append(value[:].tolist())
return col_names, col_val
def get_rh100(rh):
"""get RH percentile"""
return rh[100]
# define empty pandas dataframe
subset_df = pd.DataFrame()
for subfile in glob(path.join('downloads', '*GEDI04_A*_subsetted.h5')):
l4a_in = h5py.File(subfile, 'r')
orbit = "_".join(path.basename(subfile).split("_")[3:7])
l2a_f = glob(path.join('downloads', f'*GEDI02_A*{orbit}*_subsetted.h5'))[0]
l2a_in = h5py.File(l2a_f, 'r')
for v in list(l4a_in.keys()):
if v.startswith('BEAM'):
c_n_l4a, c_v_l4a = read_gedi_vars(l4a_in[v])
c_n_l2a, c_v_l2a = read_gedi_vars(l2a_in[v])
c_v = c_v_l4a+c_v_l2a
c_n = c_n_l4a+c_n_l2a
# Appending to the subset_df dataframe
subset_df = pd.concat([subset_df,
pd.DataFrame(map(list, zip(*c_v)), columns=c_n)])
l4a_in.close()
l2a_in.close()
# remove duplicate columns
subset_df = subset_df.loc[:,~subset_df.columns.duplicated()].copy()
# compute rh100
subset_df['rh100'] = subset_df['rh'].apply(get_rh100)
# print the first row of dataframe
subset_df.head(2)
| agbd | delta_time | lat_lowestmode_a1 | lon_lowestmode_a1 | shot_number | l4_quality_flag | pft_class | lat_lowestmode | lon_lowestmode | rh | rh100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -9999.0 | 5.628594e+07 | -2.986961 | -59.966399 | 47440000100072035 | 0 | 2 | -2.986961 | -59.966399 | [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ... | 0.0 |
| 1 | -9999.0 | 5.628594e+07 | -2.986540 | -59.966102 | 47440000100072036 | 0 | 2 | -2.986540 | -59.966102 | [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ... | 0.0 |
Quality Filter and Plot#
We can now quality filter the dataset and only retrieve the good quality shots for trees and shrub cover plant functional types (PFTs).
# MCD12Q1 PFT types
pft_legend = {0 : 'Water Bodies',
1: 'Evergreen Needleleaf Trees',
2: 'Evergreen Broadleaf Trees',
3: 'Deciduous Needleleaf Trees',
4: 'Deciduous Broadleaf Trees',
5: 'Shrub',
6: 'Grass',
7: 'Cereal Croplands',
8: 'Broadleaf Croplands',
9: 'Urban and Built-up Lands',
10: 'Permanent Snow and Ice',
11: 'Barren',
255: 'Unclassified'}
# create geopandas dtframe
gdf = gpd.GeoDataFrame(subset_df, geometry=gpd.points_from_xy(subset_df.lon_lowestmode, subset_df.lat_lowestmode), crs="EPSG:4326")
# creating mask with good quality shots and trees/shrubs pft class
mask = (gdf['l4_quality_flag']==1) & (gdf['pft_class'] <= 5 )
# plotting
gdf = gdf[['lat_lowestmode', 'lon_lowestmode', 'rh100', 'pft_class', 'agbd', 'geometry']]
gdf[mask].explore("agbd", vmax=300, cmap = "YlGn", alpha=0.5, radius=10, legend=True)
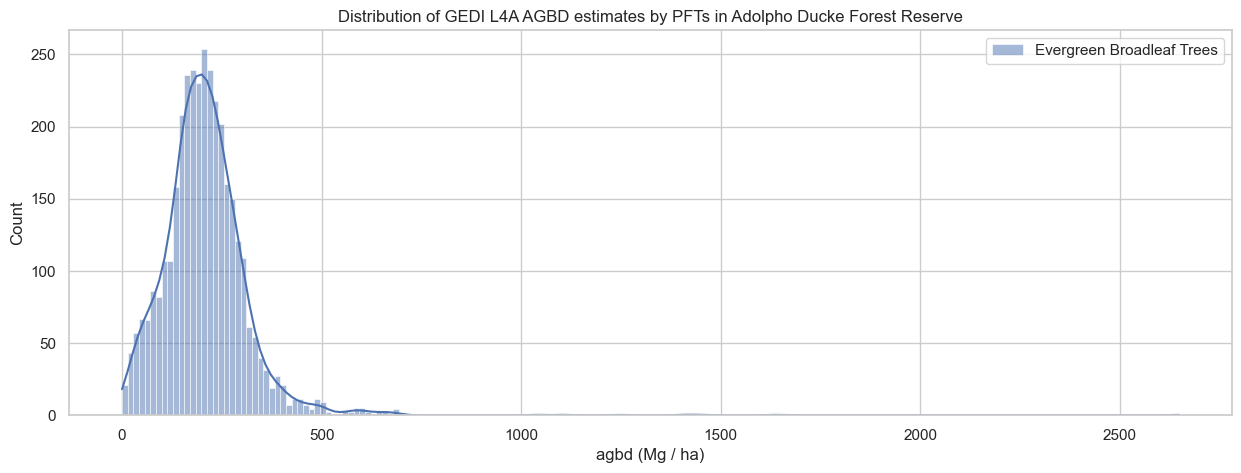
We will plot the distribution of the AGBD by plant functional types (PFTs) for good quality shots.
plt.figure(figsize=(15,5))
ax = gdf[mask].groupby('pft_class')['agbd'].\
apply(lambda x: sns.histplot(x, label = pft_legend[x.name], kde=True))
plt.xlabel('agbd (Mg / ha)')
plt.title('Distribution of GEDI L4A AGBD estimates by PFTs in Adolpho Ducke Forest Reserve')
plt.legend()
plt.show()
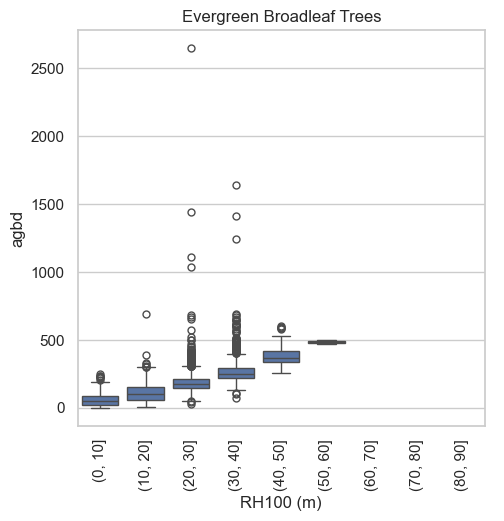
Let’s also plot how the AGBD is distributed across elevation ranges for different PFTs.
gdf['elev_bin']=pd.cut(gdf['rh100'], bins =range(0, 100, 10))
g = sns.catplot(x = "elev_bin", y = "agbd", data = gdf[mask], col="pft_class", kind="box")
g.set_xticklabels(rotation=90)
g.set_titles("{col_name}")
for ax in g.axes.flat:
ax.set_title(pft_legend[int(float(ax.get_title()))])
g.set_axis_labels("RH100 (m)")
sns.despine(top=False, right=False, left=False, bottom=False, offset=None, trim=False)